WARNING
The GGUF metadata content listed here is up to 2024-11-06. If some models add new metadata fields later, follow model publisher documentation first, or check: gguf/constants.py.
GGUF is a binary file format supported by Hugging Face Hub features, designed to optimize fast model loading and saving, with better inference efficiency in practice.
GGUF is built for GGML and GGML-based runtimes. Models developed in frameworks like PyTorch can be converted into GGUF and used by those engines.
GGUF evolved from GGJT with changes for better extensibility and usability. Target capabilities include:
- Single-file deployment: no external side files required for key model information, easier distribution and loading.
- Extensibility: add new metadata or runtime features without breaking compatibility with existing models.
mmapcompatibility: mmap maps file content into memory so programs can access file data like memory, enabling faster load/save behavior.- Ease of use: loading/saving should require only small code in different languages, without heavy external dependencies.
- All-in-One: all information needed to load the model is in one file.
GGUF Naming Rules
GGUF naming convention:
<BaseName><SizeLabel><FineTune><Version><Encoding><Type><Shard>.gguf
Each component, if present, is separated by -, so key details are visible directly from filename. In practice, historical naming diversity means not all filenames are fully parseable.
Components:
-
BaseName: descriptive base model family/architecture name; can be derived fromgeneral.basenamein GGUF metadata. -
SizeLabel: model size label, usually expressed as<expertCount>x<count><scale-prefix>for parameter category (useful for leaderboards).It can be derived from
general.size_label, or computed if missing.Single-letter scale prefixes include:
Q: quadrillion parameters.T: trillion parameters.B: billion parameters.M: million parameters.K: thousand parameters.
-
FineTune: descriptive fine-tuning purpose label, such asChat,Instruct; can be derived fromgeneral.finetune. -
Version(optional): version in formv<Major>.<Minor>. If version is absent,v1.0is often assumed as first public release. Can be derived fromgeneral.version. -
Encoding: weight encoding / quantization representation used by the model. -
Type: GGUF file type and intended use. If missing, it is treated as a typical tensor model file.LoRA: GGUF file is a LoRA adapter.vocab: GGUF file contains only vocabulary data and metadata.
-
Shard(optional): indicates the model is split into shards, format<ShardNum>-of-<ShardTotal>.ShardNum: shard index in the model; must be zero-padded to 5 digits. Shard numbering always starts from00001(not00000).ShardTotal: total shard count; also zero-padded to 5 digits.
A model filename should at least contain BaseName, SizeLabel, and Version for easy GGUF naming validation.
You can use the following regex to validate core ordering and extraction:
^(?<BaseName>[A-Za-z0-9\s]*(?:(?:-(?:(?:[A-Za-z\s][A-Za-z0-9\s]*)|(?:[0-9\s]*)))*))-(?:(?<SizeLabel>(?:\d+x)?(?:\d+\.)?\d+[A-Za-z](?:-[A-Za-z]+(\d+\.)?\d+[A-Za-z]+)?)(?:-(?<FineTune>[A-Za-z0-9\s-]+))?)?-(?:(?<Version>v\d+(?:\.\d+)*))(?:-(?<Encoding>(?!LoRA|vocab)[\w_]+))?(?:-(?<Type>LoRA|vocab))?(?:-(?<Shard>\d{5}-of-\d{5}))?\.gguf$
Examples
-
Mixtral-8x7B-v0.1-KQ2.gguf- Model name: Mixtral
- Expert Count: 8
- Parameter Count: 7B
- Version Number: v0.1
- Encoding: KQ2
-
Hermes-2-Pro-Llama-3-8B-F16.gguf- Model name: Hermes 2 pro llama 3
- Parameter Count: 8B
- Version Number: v1.0
- Encoding: F16
GGUF File Structure
GGUF (GGUF v3) file structure is shown below. It uses global alignment specified by general.alignment (though many models do not explicitly set it).
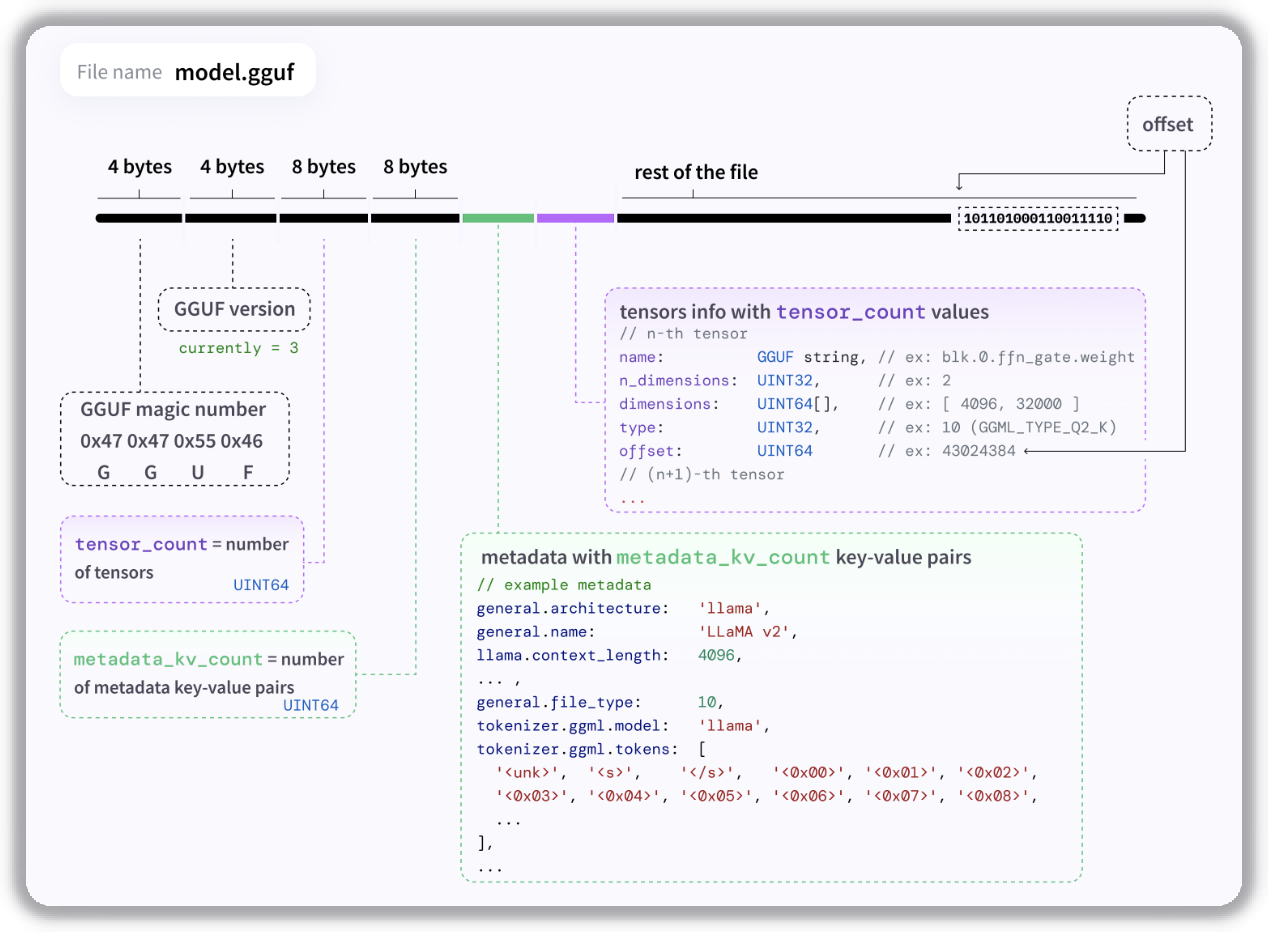
From this structure you can see a GGUF file contains format/version info, tensor count, metadata length, concrete metadata, and tensor descriptors.
Metadata (Standardized Key-Value Pairs)
The key-value pairs below are standardized. The list may grow as more use cases emerge. Naming tries to align with original model definitions where possible, making mapping easier.
Not all keys are mandatory, but all are recommended. Required keys are marked in bold. If a key is omitted, readers should treat value as unknown and fall back to default/error handling as needed.
Communities can define custom namespaced keys for extra data. To avoid conflicts, use a community prefix. For example, rustformers.* for Rustformers-specific fields.
By convention, unless otherwise specified, most count/length-like values are uint64 for future large-model support. Some models may use uint32; readers should support both.
General
Required
-
general.architecture: string: architecture name implemented by this model. Lowercase ASCII only, pattern[a-z0-9]+. Known values include:llamamptgptneoxgptjgpt2bloomfalconmambarwkvbert
-
general.quantization_version: uint32: quantization format version. Not required for non-quantized models. Required if any tensor is quantized. This is separate from tensor quantization scheme names (for example schemeQ5_K, quantization version4). -
general.alignment: uint32: global alignment value. Must be a multiple of 8. Some writers may omit it; default is assumed as32if unspecified.
General metadata
-
general.name: string: human-readable model name, ideally unique within community scope. -
general.author: string: model author. -
general.version: string: model version. -
general.organization: string: model organization. -
general.basename: string: base model name/architecture. -
general.finetune: string: optimization target for finetune. -
general.description: string: free-form model description. -
general.quantized_by: string: person who quantized the model. -
general.size_label: string: size category, for example by weight/expert count. -
general.license.*: license metadata using SPDX expressions (for example"MIT OR Apache-2.0"). Do not include license text or URL there. -
general.url: string: model homepage URL. -
general.doi: string: DOI (Digital Object Identifier), https://www.doi.org/. -
general.uuid: string: universal unique identifier. -
general.repo_url: string: model repository URL (GitHub/Hugging Face). -
general.tags: string[]: searchable tags. -
general.languages: string[]: supported languages encoded as ISO 639 two-letter codes. -
general.datasets: string[]: dataset links/references used for training. -
general.file_type: uint32: enum describing dominant tensor type in file (optional; can be inferred from tensors).ALL_F32 = 0MOSTLY_F16 = 1MOSTLY_Q4_0 = 2MOSTLY_Q4_1 = 3MOSTLY_Q4_1_SOME_F16 = 4MOSTLY_Q4_2 = 5(support removed)MOSTLY_Q4_3 = 6(support removed)MOSTLY_Q8_0 = 7MOSTLY_Q5_0 = 8MOSTLY_Q5_1 = 9MOSTLY_Q2_K = 10MOSTLY_Q3_K_S = 11MOSTLY_Q3_K_M = 12MOSTLY_Q3_K_L = 13MOSTLY_Q4_K_S = 14MOSTLY_Q4_K_M = 15MOSTLY_Q5_K_S = 16MOSTLY_Q5_K_M = 17MOSTLY_Q6_K = 18
NOTE
Source metadata
Metadata about model origin/provenance. Useful for tracing source models and upstream references when conversion/modification is involved (for example GGML-to-GGUF conversion lineage).
Usually not the primary focus in day-to-day usage.
LLM
[llm] should be replaced by architecture name. For example, llama for LLaMA, bert for BERT, etc. If architecture sections require these keys, they should be provided (not every key applies to every architecture).
[llm].context_length: uint64: alson_ctx. Context length (in tokens) used during training. For most architectures this is a hard input limit. Some non-transformer-attention architectures like RWKV may handle larger input in practice, but this is not guaranteed.[llm].embedding_length: uint64: alson_embd. Embedding size.[llm].block_count: uint64: number of attention+FFN blocks (main body of model), excluding input/embedding layer.[llm].feed_forward_length: uint64: alson_ff. Feed-forward layer size.[llm].use_parallel_residual: bool: whether parallel residual logic is used.[llm].tensor_data_layout: string: tensor layout strategy after GGUF conversion for performance. Optional; default assumedreference.reference: tensors follow original model ordering.- additional options are architecture-specific.
[llm].expert_count: uint32: number of experts in MoE models (optional for non-MoE).[llm].expert_used_count: uint32: experts used per token evaluation (optional for non-MoE).
Attention
[llm].attention.head_count: uint64: alson_head. Attention head count.[llm].attention.head_count_kv: uint64: KV head count per group in GQA. If absent or equal tohead_count, model does not use GQA.[llm].attention.max_alibi_bias: float32: max ALiBI bias.[llm].attention.clamp_kqv: float32: clamp valueCforQ,K,Vinto[-C, C].[llm].attention.layer_norm_epsilon: float32: epsilon for layer norm.[llm].attention.layer_norm_rms_epsilon: float32: epsilon for RMS norm.[llm].attention.key_length: uint32: optional key-head size; defaultn_embd / n_head.[llm].attention.value_length: uint32: optional value-head size; defaultn_embd / n_head.
Remaining key-value fields are less frequently used in most practical scenarios, so they are not expanded one by one here.
GGUF Conversion
- Hugging Face Space: https://huggingface.co/spaces/ggml-org/gguf-my-repo