WARNING
文中所列出的 GGUF 元数据部分内容截止到 24/11/06,如发现某些 model 有新增元数据信息,请以模型发布方说明为准,或者参考:gguf/constants.py, .
GGUF 是 Hugging Face Hub 内置特性支持,用于优化快速加载、保存模型的二进制文件格式,其在推理过程中具备更好的效率。
GGUF 被设计用于 GGML 和基于 GGML 的执行器进行推理。使用如 PyTorch 等框架开发的模型可以被转换为 GGUF 格式以在这些引擎上使用。
GGUF 基于 GGJT 格式,对其进行一些更改,使其更具可拓展性和更易于使用,期望具备的功能:
- 单文件部署:不需要任何外部文件来获取额外信息,便于分发和加载;
- 可拓展:可以为 GGUF 模型新增信息/GGML 执行器添加新功能而不破坏与现有模型的兼容性;
mmap兼容性:mmap 是一种内容映射文件的方法,允许程序将文件内容直接映射到内存中,从而可以像访问内存一样快速访问文件数据,因此支持使用 mmap 加载模型,可以实现模型快速加载和保存;- 易于使用:无论使用何种语言,都可以使用少量代码轻松加载和保存模型,无需外部库;
- All in One:加载模型所需的所有信息都包含在模型文件中,用户无需提供其他信息。
GGUF 命名原则
GGUF 格式的命名约定为:<BaseName><SizeLabel><FineTune><Version><Encoding><Type><Shard>.gguf。其中每个组件,如果存在,则使用 - 进行分隔,易于直接获取模型的最重要细节。由于现有 gguf 文件名的多样性,所以并不一定完全可解析。
组件包括:
-
BaseName:模型基础类型或架构的描述性名称。可以从 gguf 元数据中的general.basename中推导出来; -
SizeLabel:模型大小标签,表示为<experCount>x<count><scale-prefix>的参数权重类别(对排行榜是有用的);可从 gguf 元数据中的
general.size_label中推导出来,或者在缺失时进行计算;在计算带单个字母比例前缀的小数点时四舍五入,以帮助显示以下浮点数指数:
-
Q:千万亿参数。 -
T:万亿参数。 -
B:十亿参数。 -
M:百万参数。 -
K:千个参数。
-
-
FineTune:模型微调目的的描述性名称,如Chat、Instruct等。同样可以从 gguf 元数据中的 general.finetune 中推导出来; -
Version(可选):表示模型版本号,格式为v<Major>.<Minor>;如果模型缺失版本号,假定为 v1.0 意味着首次公开发布;同样可以从 gguf 元数据中的general.version中派生处理。 -
Encoding:表示用于模型的权重编码方案; -
Type:表示 gguf 文件的种类及其预期用途;如果缺失,表示文件默认是典型的 gguf 张量模型文件,同样可以从 gguf 元数据中LoRA:GGUF 文件是一个 LoRA 适配器;vocab:仅包含词汇数据和元数据的 GGUF 文件;
-
Shard 可选:表示模型已经被拆分为多个分片,格式为<ShardNum>-of-<ShardTotal>.-
ShardNum:此模型中的分片位置。必须是用零填充的 5 位数字。
分片编号始终从
00001开始(例如,第一个分片始终从00001-of-XXXXX开始,而不是00000-of-XXXXX)。 -
ShardTotal:此模型中的分片总数。必须是用零填充的 5 位数字。
-
所有的模型文件应至少具备 BaseName、SizeLabel、Version 以便轻松验证其是否符合 gguf 命名规范。
可以使用如下正则表达式验证是否按照正确的顺序从模型名称中获得了最基本的信息:^(?<BaseName>[A-Za-z0-9\s]*(?:(?:-(?:(?:[A-Za-z\s][A-Za-z0-9\s]*)|(?:[0-9\s]*)))*))-(?:(?<SizeLabel>(?:\d+x)?(?:\d+\.)?\d+[A-Za-z](?:-[A-Za-z]+(\d+\.)?\d+[A-Za-z]+)?)(?:-(?<FineTune>[A-Za-z0-9\s-]+))?)?-(?:(?<Version>v\d+(?:\.\d+)*))(?:-(?<Encoding>(?!LoRA|vocab)[\w_]+))?(?:-(?<Type>LoRA|vocab))?(?:-(?<Shard>\d{5}-of-\d{5}))?\.gguf$。
举例说明:
Mixtral-8x7B-v0.1-KQ2.gguf:- Model name: Mixtral
- Expert Count: 8
- Parameter Count: 7B
- Version Number: v0.1
- Encoding: KQ2
Hermes-2-Pro-Llama-3-8B-F16.gguf:- Model name: Hermes 2 pro llama 3
- Parameter Count: 8B
- Version Number: v1.0
- Encoding: F16
GGUF 文件结构
GGUF (GGUF v3)文件结构如下。使用在 general.alignment 字段中指定的全局对齐方式(不过,大部分模型似乎都没这个东西)。
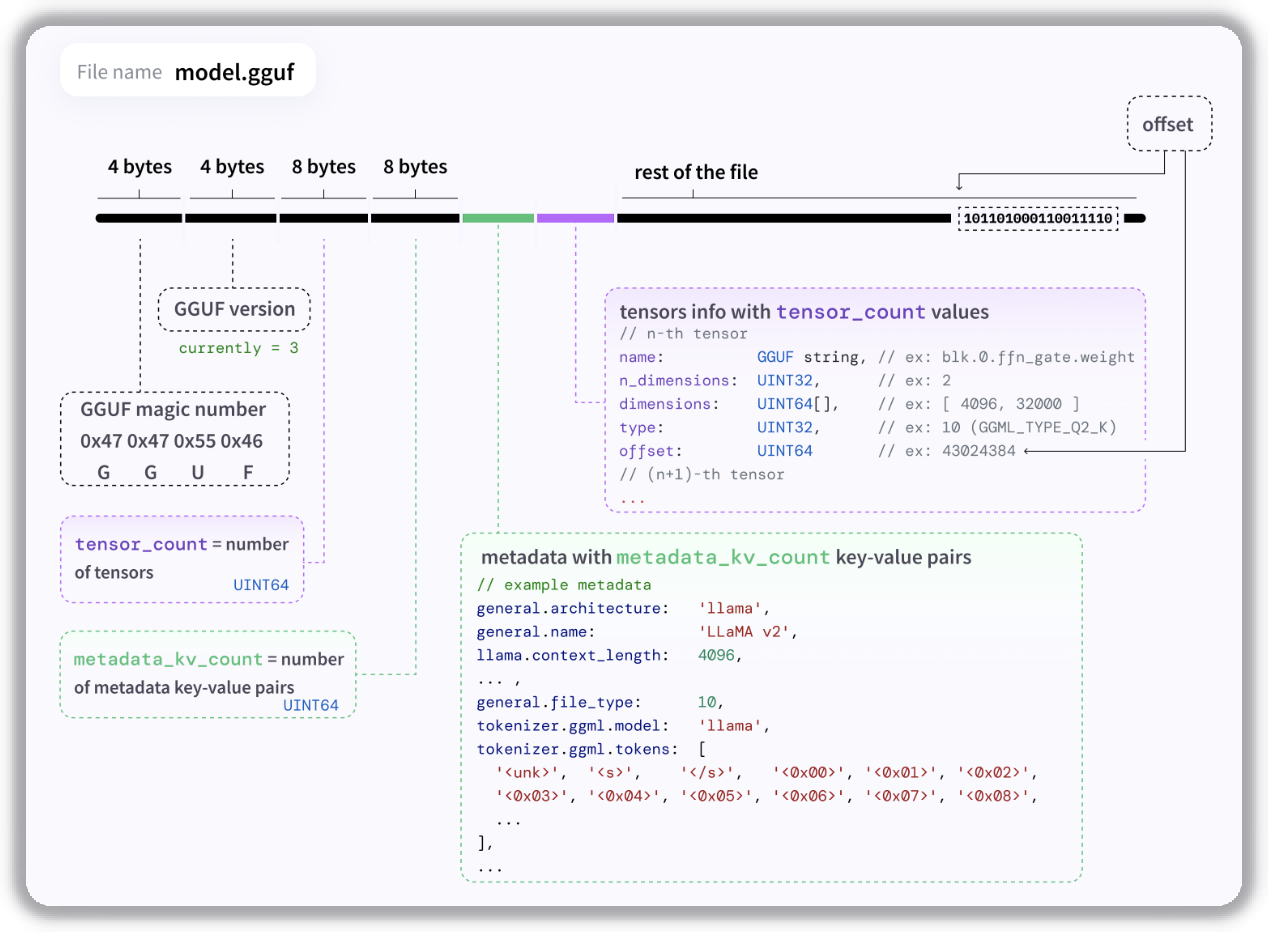
这里可看出 GGUF 模型文件表示了 GGUF 格式、版本、tensor 数量、元数据长度、具体的元数据信息与张量信息。
元数据(标准化键值对)
以下键值对已标准化。随着更多用例的发现,此列表可能会在未来增加。在可能的情况下,名称与原始模型定义共享,以便更容易在两者之间进行映射。
并非所有这些都是必需的,但都建议使用。必需的键用粗体表示。对于省略的对,读者应假定该值未知,并根据需要默认为默认值或错误。
社区可以开发自己的键值对来携带额外的数据。但是,这些应该使用相关社区名称进行命名空间,以避免冲突。例如, rustformers 社区可能会使用 rustformers. 作为其所有键的前缀。
按照惯例,除非另有说明,大多数计数/长度/等都是 uint64 。这是为了将来能够支持更大的模型。一些模型可能会使用 uint32 作为其值;建议读者同时支持这两种情况。
General
Required
general.architecture: string:描述此模型实现的架构。仅允许使用小写 ASCII 字符,且只能包含[a-z0-9]+字符。已知值包括:llamamptgptneoxgptjgpt2bloomfalconmambarwkvbert
general.quantization_version: uint32:量化格式的版本。如果模型未量化(即没有量化张量),则不需要。如果有任何张量被量化,则必须存在。这与张量本身的量化方案是分开的;量化版本可能会更改,而方案的名称不变(例如,量化方案是 Q5_K,量化版本是 4)。general.alignment: uint32:如前所述,要使用的全局对齐方式。这可以变化以允许不同的对齐方案,但它必须是 8 的倍数。一些写入器可能不会写入对齐方式。如果未指定对齐方式,则假定为32。
General metadata
-
general.name: string:模型的名称。这应该是一个人类可读的名称,可用于标识模型。它应该在定义模型的社区内是唯一的。 -
general.author: string:模型的作者。 -
general.version: string:模型的版本。 -
general.organization: string:模型的组织。 -
general.basename: string:模型的基本模型名称/架构。 -
general.finetune: string:基础模型针对什么进行了优化。 -
general.description: string:模型的自由格式描述,包括其他字段未涵盖的任何内容。 -
general.quantized_by: string:对模型进行量化的个人的名称。 -
general.size_label: string:模型的大小类别,例如权重和专家的数量。 -
general.license.*:模型的许可证等信息,以 SPDX 许可证表达式表示(例如"MIT OR Apache-2.0)。不要包含任何其他信息,例如许可证文本或许可证的 URL。 -
general.url: string:模型主页的 URL。这可以是 GitHub 仓库、论文等。 -
general.doi: string: 数字对象标识符 (DOI) https://www.doi.org/。 -
general.uuid: string:通用唯一标识符。 -
general.repo_url: string:模型存储库的 URL,例如 GitHub 存储库或 HuggingFace 存储库。 -
general.tags: string[]:可作为搜索引擎或社交媒体搜索词的标签列表。 -
general.languages: string[]:模型支持的语言。编码为 ISO 639 两个字母代码。 -
general.datasets: string[]:模型训练所依据的数据集的链接或引用。 -
general.file_type: uint32:描述文件中大多数张量类型的枚举值。可选;可以从张量类型推断。ALL_F32 = 0MOSTLY_F16 = 1MOSTLY_Q4_0 = 2MOSTLY_Q4_1 = 3MOSTLY_Q4_1_SOME_F16 = 4MOSTLY_Q4_2 = 5(支持已移除)MOSTLY_Q4_3 = 6(支持已移除)MOSTLY_Q8_0 = 7MOSTLY_Q5_0 = 8MOSTLY_Q5_1 = 9MOSTLY_Q2_K = 10MOSTLY_Q3_K_S = 11MOSTLY_Q3_K_M = 12MOSTLY_Q3_K_L = 13MOSTLY_Q4_K_S = 14MOSTLY_Q4_K_M = 15MOSTLY_Q5_K_S = 16MOSTLY_Q5_K_M = 17MOSTLY_Q6_K = 18
NOTE
Source metadata
关于此模型来源的信息。这对于跟踪模型的出处以及在模型被修改时找到原始来源很有用。例如,对于从 GGML 转换而来的模型,这些键将指向转换前的模型。
通常不用特别关注。
LLM
[llm] 用于填写特定 LLM 架构的名称。例如, llama 表示 LLaMA, bert 表示 Bert 等。如果在架构部分中提到,则该架构需要,但并非所有键都适用于所有架构,具体需要参考相关部分以获取更多信息。
[llm].context_length: uint64:也称为n_ctx。模型训练时上下文的长度(以词元为单位)。对于大多数架构,这是输入长度的硬限制。像 RWKV 这样不依赖于 transformer 式注意力的架构可能能够处理更大的输入,但这不能保证。[llm].embedding_length: uint64:也称为n_embd。嵌入层大小。[llm].block_count: uint64:注意力+前馈层的块数(即 LLM 的大部分)。不包括输入或嵌入层。[llm].feed_forward_length: uint64:也称为n_ff。前馈层的长度。[llm].use_parallel_residual: bool:是否应使用并行残差逻辑。[llm].tensor_data_layout: string:当模型转换为 GGUF 时,可能会重新排列张量以提高性能。此键描述张量数据的布局。这不是必需的;如果不存在,则假定为reference。reference: tensors are laid out in the same order as the original modelreference:张量的布局与原始模型的布局顺序相同- further options can be found for each architecture in their respective sections 在各自的部分中可以找到每个架构的更多选项。
[llm].expert_count: uint32:MoE 模型中的专家数量(对于非 MoE 架构为可选)。[llm].expert_used_count: uint32:每个令牌评估期间使用的专家数量(对于非 MoE 架构是可选的)。
Attention
[llm].attention.head_count: uint64:也称为n_head。注意力头的数量。[llm].attention.head_count_kv: uint64:在分组查询注意力(Grouped-Query-Attention)中每个组使用的头数。如果不存在或存在且等于[llm].attention.head_count,则模型不使用 GQA。[llm].attention.max_alibi_bias: float32:用于 ALiBI 的最大偏差。[llm].attention.clamp_kqv: float32:值(C)用于将Q、K和V张量的值限制在([-C, C])之间。[llm].attention.layer_norm_epsilon: float32:层归一化的 epsilon。[llm].attention.layer_norm_rms_epsilon: float32:层 RMS 归一化的 epsilon。[llm].attention.key_length: uint32:键头的可选大小。如果未指定,则为n_embd / n_head。[llm].attention.value_length: uint32:值头部的可选大小。如果未指定,则为n_embd / n_head。
其余键值通常不会关注/较少关注,不再一一列出。
GGUF 转换
- hugging face space:https://huggingface.co/spaces/ggml-org/gguf-my-repo;