CoT was proposed shortly after prompt engineering for large models became popular. Its core “magic” can be summarized in one sentence: “Let’s think step by step.” A common explanation is that forcing LLMs to output more task-related intermediate text can improve next-token prediction accuracy. More recently, the slow-thinking style in o1-preview has also been seen as an engineering implementation of CoT. Because of this, some people started to claim that CoT demonstrates unlimited reasoning capability and may push us closer to AGI.
But is that really true?
From my own experience using LLMs in different downstream NLP tasks, CoT can improve outputs in some scenarios, but the gains are often limited, and in many cases there is no obvious benefit.
This article reviews recent research on CoT’s negative effects on LLM performance. Original paper: Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse.
Introduction
Although model cognition is not identical to human cognition, we can still use cases where “thinking” harms human performance as references, and hypothesize that thinking may also hurt model performance.
The authors selected six task types from well-established psychology literature to test CoT’s impact on LLM performance. Their results show that CoT does not improve performance universally. In implicit statistical learning, facial recognition, and classification tasks with exception patterns, performance drops significantly across several SOTA models. The study also demonstrates the feasibility of using human psychology as a lens for understanding large models.
Methodology
The study is built on two key premises:
- Verbalized thinking or over-deliberation can hurt human performance.
- The same constraints that hurt humans may generalize to language models.
Six predesigned task settings were used:
-
Implicit Statistical Learning: Tests whether CoT hurts performance on classification tasks with hidden grammatical structures. Based on psychological findings that humans can perform worse on language-reasoning-like patterns, the authors hypothesized similar effects for LLMs.
In this paper, hidden-grammar classification means generating strings with synthetic rules and asking LLMs to judge whether a new string follows the hidden rule (binary classification).
-
Facial Recognition: Models identify faces in images. Based on the human phenomenon that verbalizing facial features can reduce recognition accuracy, the authors hypothesized CoT would also hurt model face recognition.
-
Classifying Data with Patterns that contain Exceptions: Simulates learning from labeled data containing exceptions. The hypothesis is that CoT may increase the number of learning rounds because, like humans, models may over-prefer simple rules and ignore exceptions.
-
Explaining a logical inconsistency: In logical-consistency tasks, models detect contradictions between two statements. This task often causes human language-reasoning difficulty.
-
Spatial Intuitions: Models infer liquid position in a tilted container. This depends on spatial/motion intuition, and psychology suggests humans often do poorly when forced into verbal reasoning. The study tests whether models show similar behavior.
-
Aggregating Features for a Decision: Models aggregate multi-dimensional information to make decisions. Since information overload often hurts humans under CoT, the hypothesis is that CoT may not help here.
For each task, the authors compared zero-shot prompting vs. CoT prompting across mainstream LLMs/LMMs (including GPT-4o, Claude 3.5, Llama, etc.).
Results
Implicit Statistical Learning
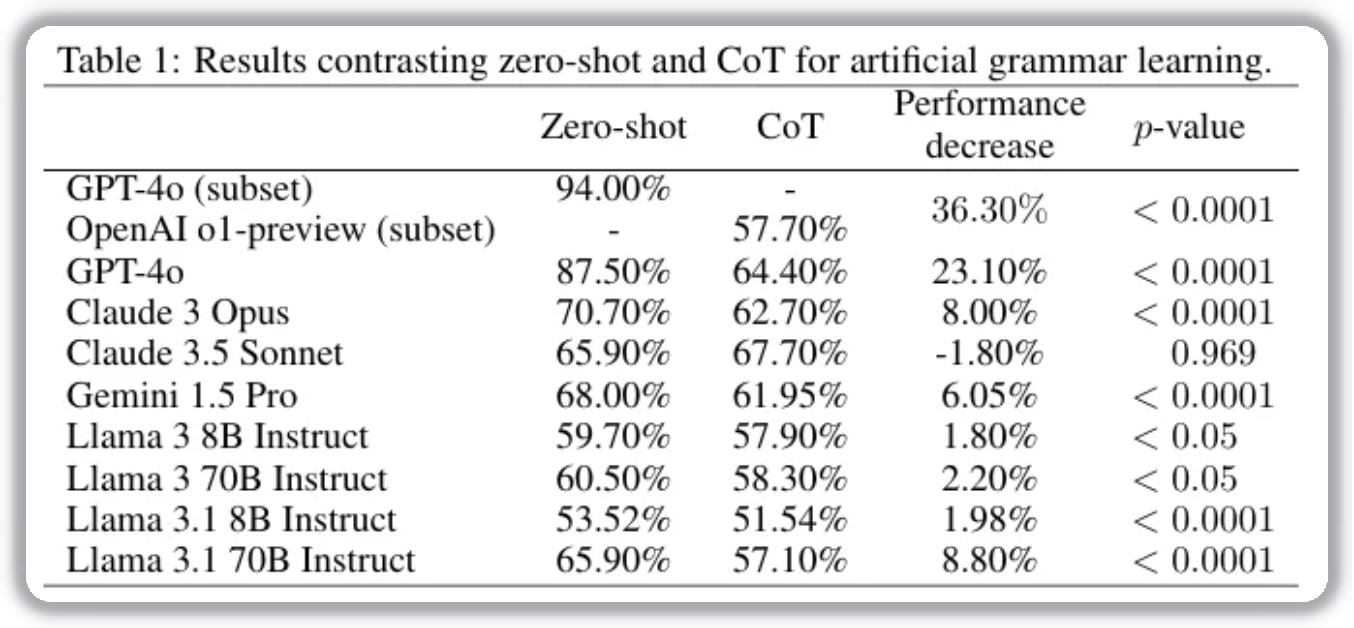
The task evaluates classification on sequences generated from specific grammar structures: 4,400 classification problems based on 100 finite-state grammar (FSG) structures. Each test provides 15 examples and asks the model to classify new sequences.
Results show a clear performance drop with CoT prompting. Notably, OpenAI o1-preview drops by 36.3% in accuracy. This suggests that when models over-rely on step-by-step reasoning, CoT can suppress their ability to capture implicit statistical patterns.
Facial Recognition
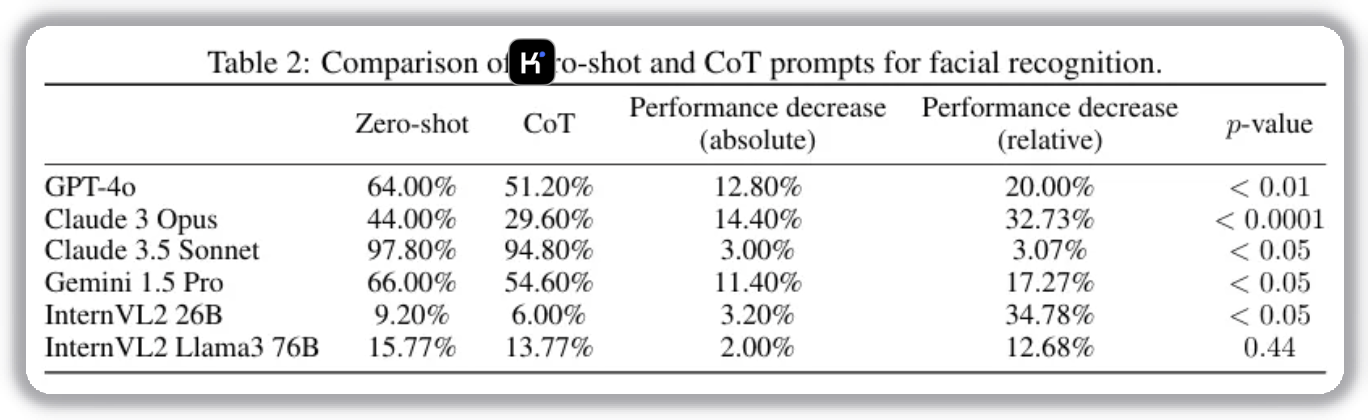
This setting evaluates whether CoT harms face recognition, inspired by the “verbal overshadowing” effect in psychology. Models complete 500 tasks, each matching an initial face to 1 out of 5 candidates.
Verbal overshadowing means that verbalization can interfere with perceptual memory and reduce recognition quality.
Results show that all tested LMMs perform worse under CoT, consistent with the hypothesis.
Classifying Data with Exception Patterns
This task tests how models handle classification with major/minor features and exception labels. Models learn iteratively across rounds, with the objective of minimizing rounds needed.
Experiments on GPT-4o, Claude 3.5 Sonnet, and Claude 3 Opus show that CoT significantly increases the number of rounds required. On average, GPT-4o needs about 4x more rounds with CoT than with direct prompting. Claude 3.5 Sonnet and Claude 3 Opus also require more than 2x rounds.
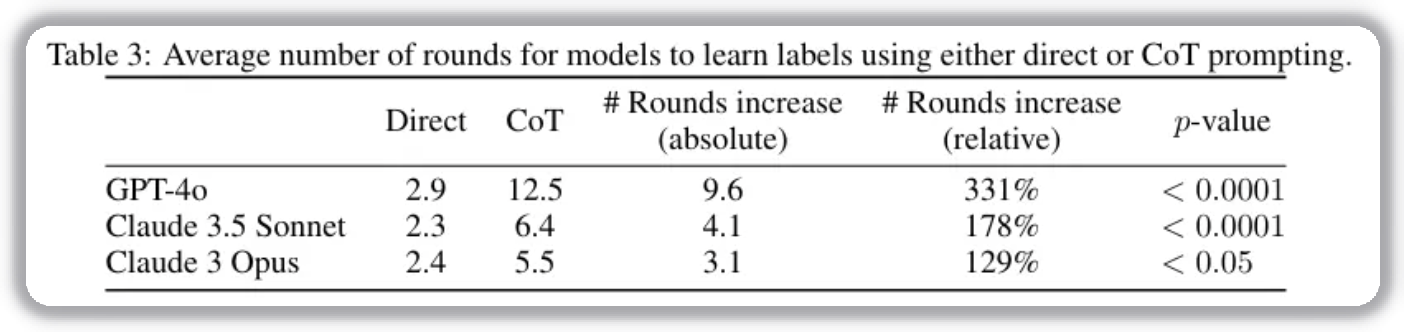
Further analysis on GPT-4o shows that direct prompting can reach perfect classification in round 2 or 3, while CoT reaches only 8/10 correct objects by rounds 4–5. This indicates CoT can bias models toward rule-based reasoning and away from known correct answers, greatly reducing classification efficiency.
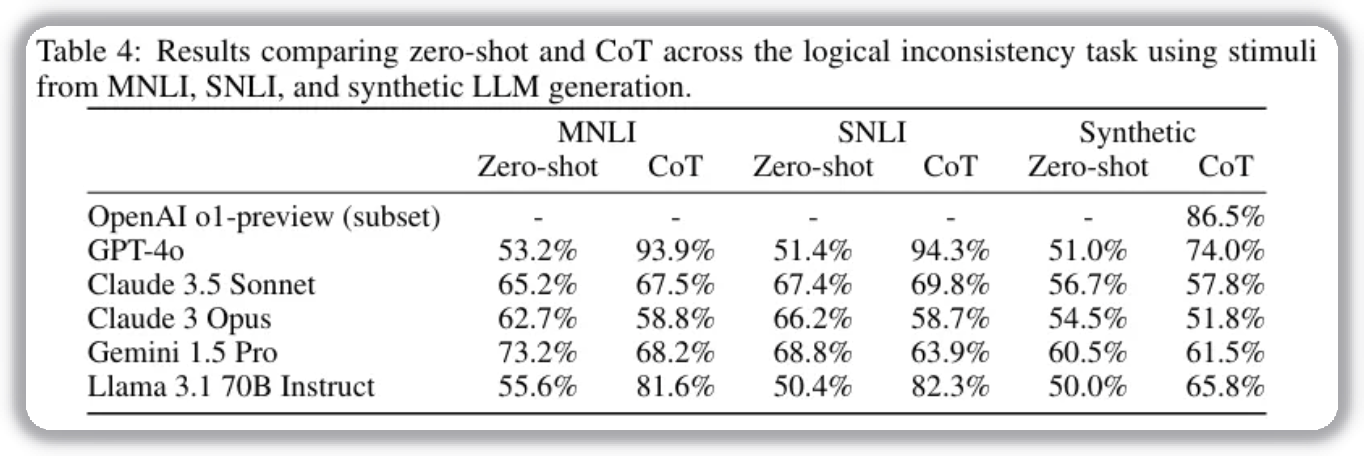
Explaining Logical Inconsistency
The study finds CoT increases the chance that models ignore contradictions. During step-by-step reasoning, models may focus on complex logic structures and miss direct contradiction detection. This suggests limitations of CoT in tasks requiring precise logical verification.
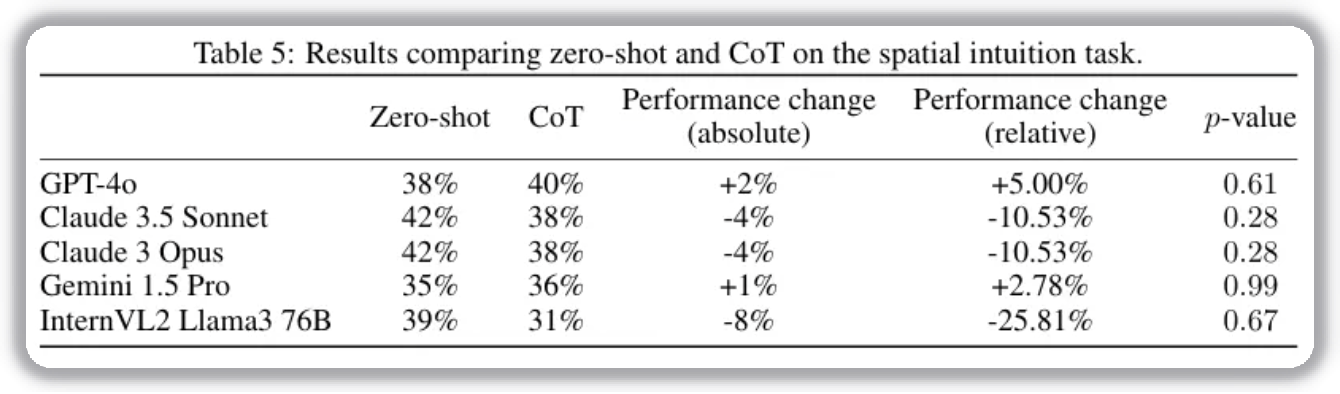
Spatial Intuition
In this setting, models solve “tilted cup” questions to infer water level position. These tasks rely on spatial/motion intuition, where humans often do better with non-verbal thinking.
Models receive visual prompts and multiple-choice options. Results show CoT has no significant effect. This suggests model reasoning in spatial/motion tasks differs from human intuition, so CoT’s negative impact is limited here.
Feature Aggregation Decision
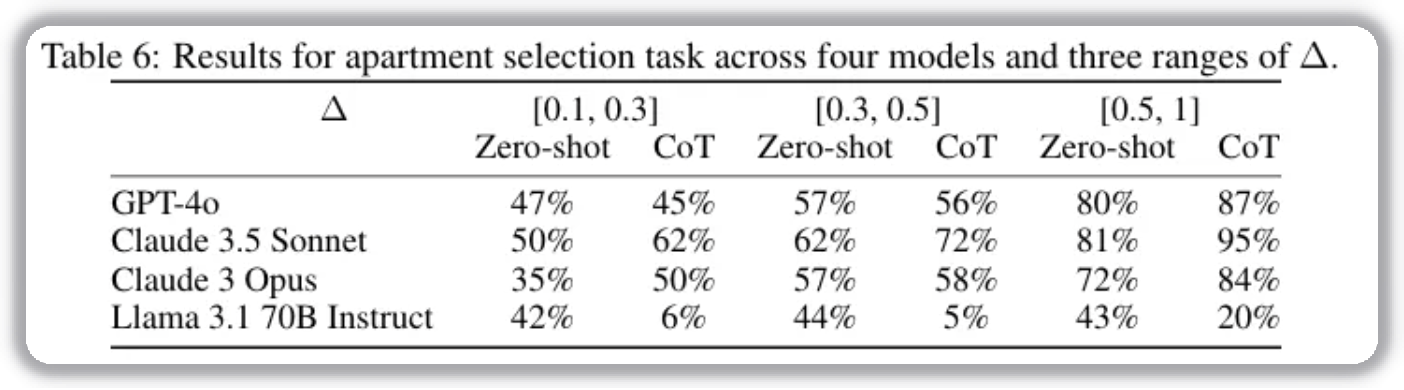
This task simulates multi-feature decisions (such as choosing a house) and tests the impact of information overload. Humans often perform worse under CoT due to memory limits. Models, in contrast, retain full context and can aggregate/evaluate features without memory loss.
Results show CoT improves performance in high-context-memory tasks, indicating CoT can have positive effects when information retention is critical.
Closing Thoughts
I noticed two interesting points in the feature-aggregation test:
- OpenAI and Llama models show performance drops, while Claude models are more consistent and show clear gains.
- Based on Anthropic’s disclosed model hierarchy, Opus should be clearly stronger than Sonnet, but Sonnet performs clearly better in this task.
Also, for reasoning tasks, I suspect poor CoT prompt design can heavily affect final outcomes. We should interpret “CoT hurts performance” conclusions cautiously and in context.